文章信息:Andres Gomez-Lievano, Oscar Patterson-Lomba, & Ricardo Hausmann. (2016). Explaining the prevalence, scaling and variance of urban phenomena. Nature Human Behaviour: 1(1), 1–6. https://doi.org/10.1038/s41562-016-0012
阅读笔记:王舜奕
阅读时间:2019年4月24日
1.选题视角:
许多城市现象流行规模随人口规模呈现出有系统的变化。根据对美国城市活动的观察,流行规模遵循随人口规模的幂律尺度(二者的量级呈线性关系),相同规模的城市,不同的现象具有不同的流行性和规模指数。这些现象普遍存在于各种城市活动中。因此:
①提出一种机制来同时解释城市事件流行和人口的关系;
②通过构建模型来预测未来城市事件流行的可能性。
(现象描述—机制解释—模型预测)
2.过去研究的不足:
大多数理论都是基于对基本现象的网络描述,并从网络中链接的数量随着节点数量的增加而增加的方式,在一定的能量或预算约束下,推导出尺度特性。
本研究提出了一种不同的机制来改进之前的解释,因为它不仅生成规模尺度,而且还可以解释不同现象之间的相对流行程度、规模以及相同规模城市之间的现象流行率的差异。
3.数据来源:
开源统计数据,包括就业、创新、教育、犯罪以及传染病。
4.分析方法:
①回归分析(Regression analysis.): 用于相关性和线性关系构建
②核密度分析(Kernel density estimation):用于统计学特征描述
5.结论:
研究提出一个理论,将已有的经济复杂性模型、文化进化模型结合起来,得出城市事件规模的模型。该理论解释了不同尺度指数和现象之间的流行率的差异。一种现象的发生必须同时存在若干必要的补充因素,而因素的多样性与人口规模呈对数关系。该模型揭示:需要更多因素的现象将会变得不那么流行。这一理论适用于教育、就业、创新、疾病和犯罪等方面的数据,可以预测一种现象在各个城市的流行程度,给出城市事件流行程度的信息。
6.思考:
文章揭示了一个规律:规模更大的城市会有更高的因子的多样性。
不同种类的因子对应不同层级的城市:哪些因子可以维持城市的基本运转,哪些因子可以促使城市向更高层级发展?
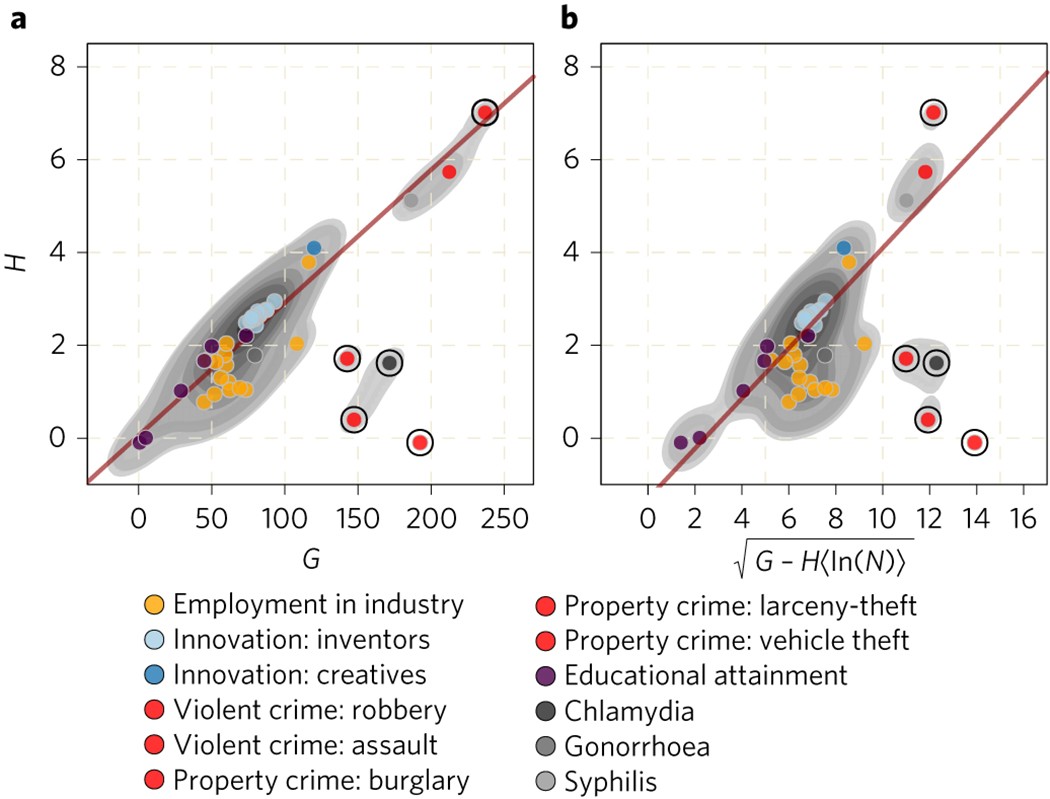
图 参数G、H的推断值与43种不同城市现象之间的关系
a,b,理论并没有限制它们的值,因此图中用灰色显示了核密度估计的轮廓,以揭示潜在的模式和关系。根据估计的密度,提出了一种线性关系。这条线是估计的鲁棒回归,它排除了用黑色圈起来的前五个异常值,这是估计密度最低的现象。在这两个小组中,异常值是相同的:“抢劫”、“严重攻击”、“盗窃”、“盗窃”和“衣原体”。两个面板的线性趋势是一个经验表明,系数s1和s2在各种现象中基本上是常数。
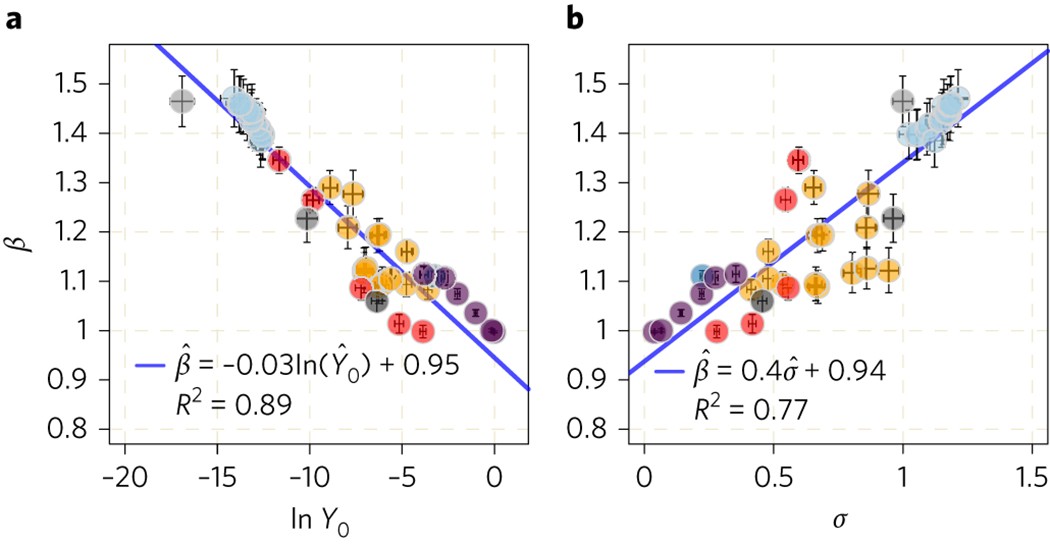
图 预测
a, b,理论预测负线性关系β和ln Y0 (a),β和积极的关系和σ(b), 1的拦截。因此,有一个隐含的负线性关系σ和ln Y0零拦截。两幅图均显示所研究的43种城市现象的点估计值(彩色圆盘的中心)和尺度定律估计参数(误差条)的相应标准误差。
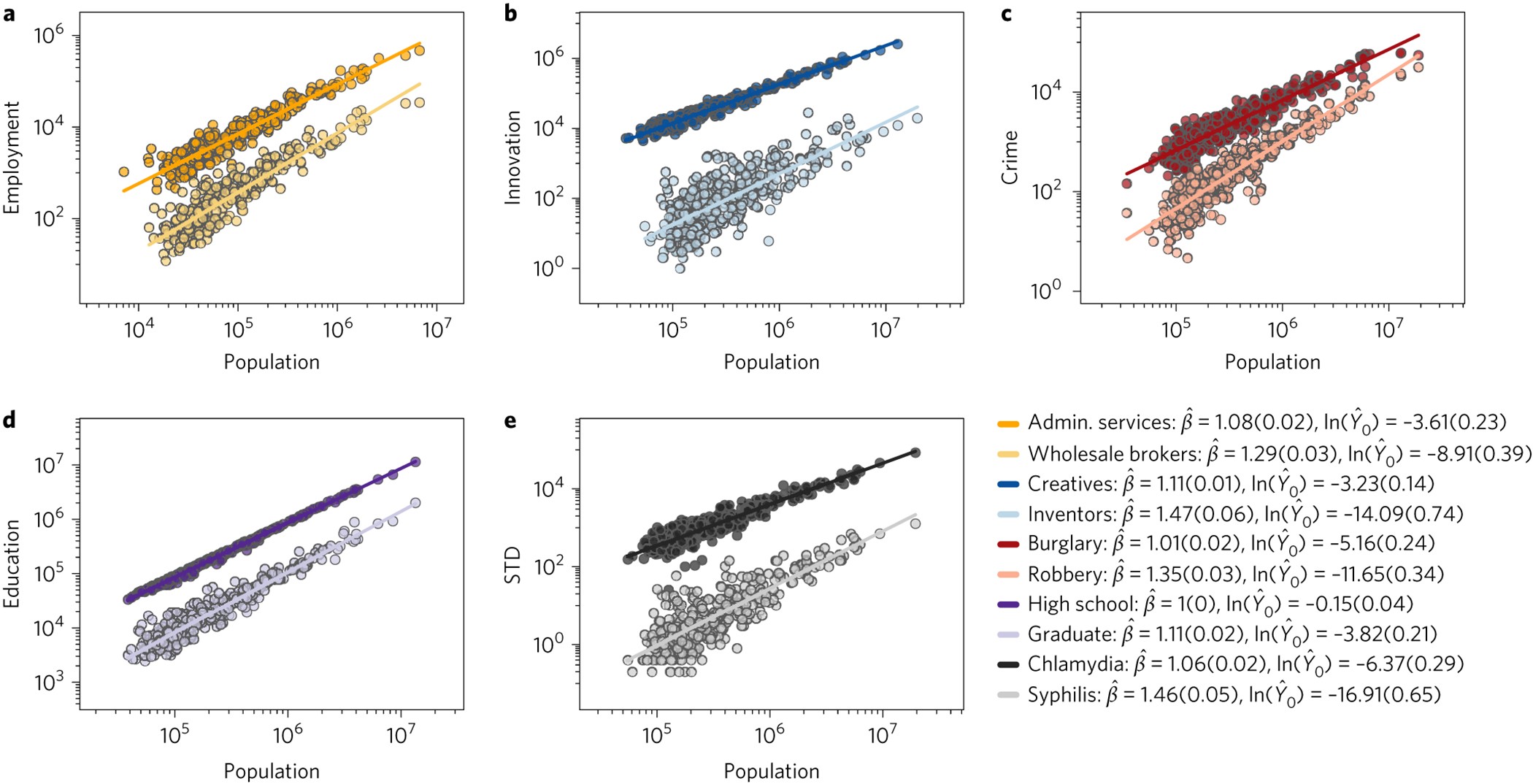
图 我们试图解释的十种不同城市现象中的四个事实
患病率随人口规模呈幂律标度,不同现象在相似规模的城市有不同的总体患病率、不同的标度指数和方差。a e,散点图显示了以下每种情况下的人数:两个行业的就业(a)、两种创新活动(b)、两类暴力犯罪(c)、具有特定教育水平的人(d)和两种性传播疾病(e)。Hat(^)表示参数的统计估计。这些线表示模型E{Y|N}=Y0N²的最佳拟合(有关数据源和其他信息,请参阅方法)。
原文链接:https://www.nature.com/articles/s41562-016-0012
